
DeepSeek本地化部署超简单,比装个office还简单
本以为DeepSeek本地化部署有多难,实际上验证后很简单,任何普通人只要会电脑的都很容易上手,大约30分钟可完成本地化部署。
本以为DeepSeek本地化部署有多难,实际上验证后很简单,任何普通人只要会电脑的都很容易上手,大约30分钟可完成本地化部署。
1.基于条件和画像筛选用户的业务分析和实现
春节假期回来,一睁眼全是王炸级的开源模型 DeepSeek-R1!
Chats的思维链演示:
Streamlit作为一个简单而强大的用于快速构建和部署数据科学和机器学习项目,也提供了强大的 会话状态管理功能,即 st.session_state。
这篇文章主要介绍一个接口 AttributeModifier,它很好的解决了这些弊端,可以实现样式的集中管理和复用,支持 跨文件调用封装好的样式类
子类类型赋值给父类 Father f1 = New Son() 调用子类方法报错。 调用父类方法OK。这个就是多态
支持多平台,支持的功能有
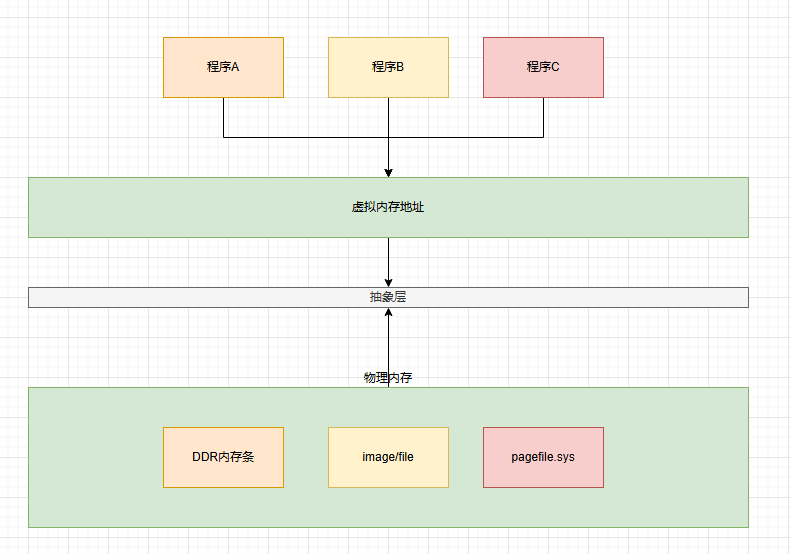
经常有人把 Java 内存区域笼统地划分为堆内存(Heap)和栈内存(Stack),这种划分方式直接继承自传统的 C、C++程序的内存布局结构,在 Java 语言就显得有些粗糙了,实际的内存区域划分是要更复杂一下。如下所示:
达梦一哥们找我优化条SQL,反馈在DM8数据库执行时间很慢出不来结果, 监控工具显示这条SQL的执行时间需要20多万毫秒,安排。

随着互联网的发展,国内信息化建设进入了基于web应用的核心阶段,java也随之腾空崛起,成为了现在热门的编程语言之一。java web发展势头正猛,越来越多人看好这个行业,都准备进军该领域,但是又不知道从哪里开始学起?首先要学习java...
在SaaS与AI应用的演进过程中,合理的架构设计至关重要。本节将详细介绍其五个核心层次:
Zotero原本经常被用来当作论文数据库,可以导入自己关注的各个领域的文章,还可以云同步到其他设备上。而且因为Zotero强大的PDF处理能力,有时候也会被拿来当科研论文的PDF阅读器。那么如果在读论文的时候直接导入一个大模型AI助手,那么...
“不用专业术语,就像和朋友聊天一样描述需求”。
在未来的几年里,人工智能系统将对人们的工作方式产生重大影响。因此,我们推出了 Anthropic Economic Index,这是一个旨在理解人工智能对劳动力市场和经济的长期影响的倡议。
这些方法提供了基本的文件操作功能,包括获取配置、打开文件对话框和保存文件
-(代码示例说明思维路径的简化) [6]*
作为程序员,怎么能忍受?于是乎去寻找deepseek供应商,对比了下常用的供应商,比如阿里百炼的通义、字节火山的豆包、腾讯的混元、fireworks、together等等。发现其中还真有不少好用且稳定的供应商。
最简单的例子是,您可能希望将长文档拆分为较小的块,以适应模型的上下文窗口。LangChain具有许多内置的文档转换器,可以轻松地拆分、合并、过滤和其他操作文档。
注: 如果评估模型的输出结果是二元分类,那么评估会相对简单,因为可使用的解释性分类指标有很多 (如准确率、召回率和精确率)。但如果输出是在某个范围内的分数,评估起来就会困难一些,因为模型输出和参考答案的相关性指标很难与分数映射的非常准确。
1.营销系统引入MQ实现异步化来进行性能优化
备忘录模式主要用于捕获一个对象的内部状态,以便在将来的某个时候 恢复此状态。
在前端开发的广袤宇宙中,Vue2 框架宛如一把闪耀的钥匙,为开发者们开启了一扇通往高效、灵活构建用户界面的大门。随着互联网技术的飞速发展,前端开发的复杂性与日俱增,对开发工具和框架的要求也愈发严苛。Vue2 正是在这样的背景下应运而生,凭借...
Anoii网络库的事件循环:
今天我在地址栏随手敲了个ai.com,结果网页”唰”地一下——居然跳到了国产AI新贵DeepSeek的官网!这感觉就像在胡同口买煎饼,结果老板递给我一块金砖啊
最近一直在研究DeepSeek,作为应用层的选手,自然不会 傻乎乎的想要去了解底层,我的关注点其实一直在 成本两个字上,因为这里涉及到了新的 AI应用技术路径选择。
通过使用商业版和社区版的经验,有几个痛点:
GitHub地址: https://github.com/browser-use/browser-use。目前已经获得了27.3k颗stars,2.7kforks,看得出来是一个比较热门的项目。我在上手体验了之后,发现确实是一个很有趣的项目...